Data Analysis/web crawling
[Crawling] 부모 태그 접근하기 / sibling / generator
아이스베어 :)
2021. 6. 8. 11:43
728x90
반응형
* 본 포스팅은 주피터 노트북에서 진행하였다.
tag_span = soup.span
tag_title = soup.title
span_parent = tag_span.parent
title_parent = tag_title.parentprint(tag_span)
print(tag_title)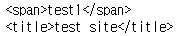
print(span_parent)
print(title_parent)
span_parents = tag_span.parents
title_parents = tag_title.parentsprint(span_parents)
print(title_parents)
generator라 반복문을 쓸 수 있다.
for i in span_parents:
print(i)
text만 골라 출력이 가능하다.
for i in title_parents:
print(i.text)
sibling 관계(형제)
html = """<html> <head><title>test site</title></head> <body> <p><a>test1</a><b>test2</b><c>test3</c></p> </body></html>"""
soup = BeautifulSoup(html,'lxml')tag_a=soup.a
tag_a #<a>test1</a>
tag_b=soup.b
tag_b #<a>test2</a>
tag_c=soup.c
tag_c #<a>test3</a>teg_a_nexts = tag_a.next_siblings
tag_a #<a>test1</a>
tag_a_prevs = tag_a.previous_siblings
tag_a_prevs #<generator object PageElement.previous_siblings at 0x00000243F01AD120>
for sibling in teg_a_nexts:
print(sibling)
728x90
반응형