728x90
반응형
html = """<html> <head><title>test site</title></head> <body> <p>test1</p><p class="d">test2</p><p class="c">test3</p></p> </body></html>"""
soup = BeautifulSoup(html,'lxml')print(soup.find_all('p',class_='d'))
print(soup.find_all('p',class_='c'))
기존 속성(attribute) class와 구분하기 위해 _가 추가되었다.
print(soup.find_all('p', text='test1'))
print(soup.find_all('p', text='t'))
하나의 요소만 가져오는 find
print(soup.find('p'))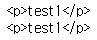
제한을 가할때 limit 사용
print(soup.find_all('p', limit=1)[0])
print(soup.find_all('p', limit=2))
select () 함수를 이용하면 find_all() 처럼 리스트로 반환한다. 하지만 select()는 css 셀렉터를 활용하여 원하는 요소에 접근할 수 있다.
html = """<html> <head><title>test site</title></head> <body> <p id="i" class="a">test1</p><p class="d">test2</p><p class="d">test3</p></p> <a>a tag</a> <b>b tag</b></body></html>"""
soup = BeautifulSoup(html,'lxml')print(soup.select('.d'))
print(soup.select('p.d'))
print(soup.select('#i'))
print(soup.select('p#i'))
태그를 지우는 extract
a=soup.body.extract()
a

soup = BeautifulSoup(html,'lxml')
for tag in soup.select('p'):
print(tag.extract())
print('제거완료')
print(soup)
728x90
반응형
'Data Analysis > web crawling' 카테고리의 다른 글
| [Crawling] 사이트 분석/ 크롤러 만들기 (0) | 2021.06.08 |
|---|---|
| [Crawling] 정규식을 이용한 bs4 고급 스킬 / 정규식 정리 / match와 search 비교 (0) | 2021.06.08 |
| [Crawling] 요소에 접근하기 (0) | 2021.06.08 |
| [Crawling] 부모 태그 접근하기 / sibling / generator (0) | 2021.06.08 |
| [Crawling] Generator 만들기 / 자바스크립트 yield와 비교 (0) | 2021.06.08 |