728x90
반응형
* 본 포스팅은 주피터 노트북에서 진행되었다.
Selenium
사용자가 아닌 프로그램이 웹 브라우저를 제어할 수 있게 해주는 라이브러리이다.
서버와 클라이언트로 나누는데, 웹 브라우저 종류마다 클라이언트 프로그램이 별도로 필요하다.
from selenium import webdriver
url = "https://pjt3591oo.github.io"
driver = webdriver.Chrome('chromedriver')
driver.get(url)selected_link = driver.find_element_by_class_name('p')
print(selected_link)
print(selected_link.tag_name)
print(selected_link.text)
selected_selector = driver.find_element_by_css_selector('div.home div.p a')
print(selected_link)
print(selected_link.tag_name)
print(selected_link.text)
이제 웹을 제어해 보았다.
selected_selector.click() #코드를 이용하여 선택된 항목에 클릭 이벤트이 코드를 실행하면 자동적으로
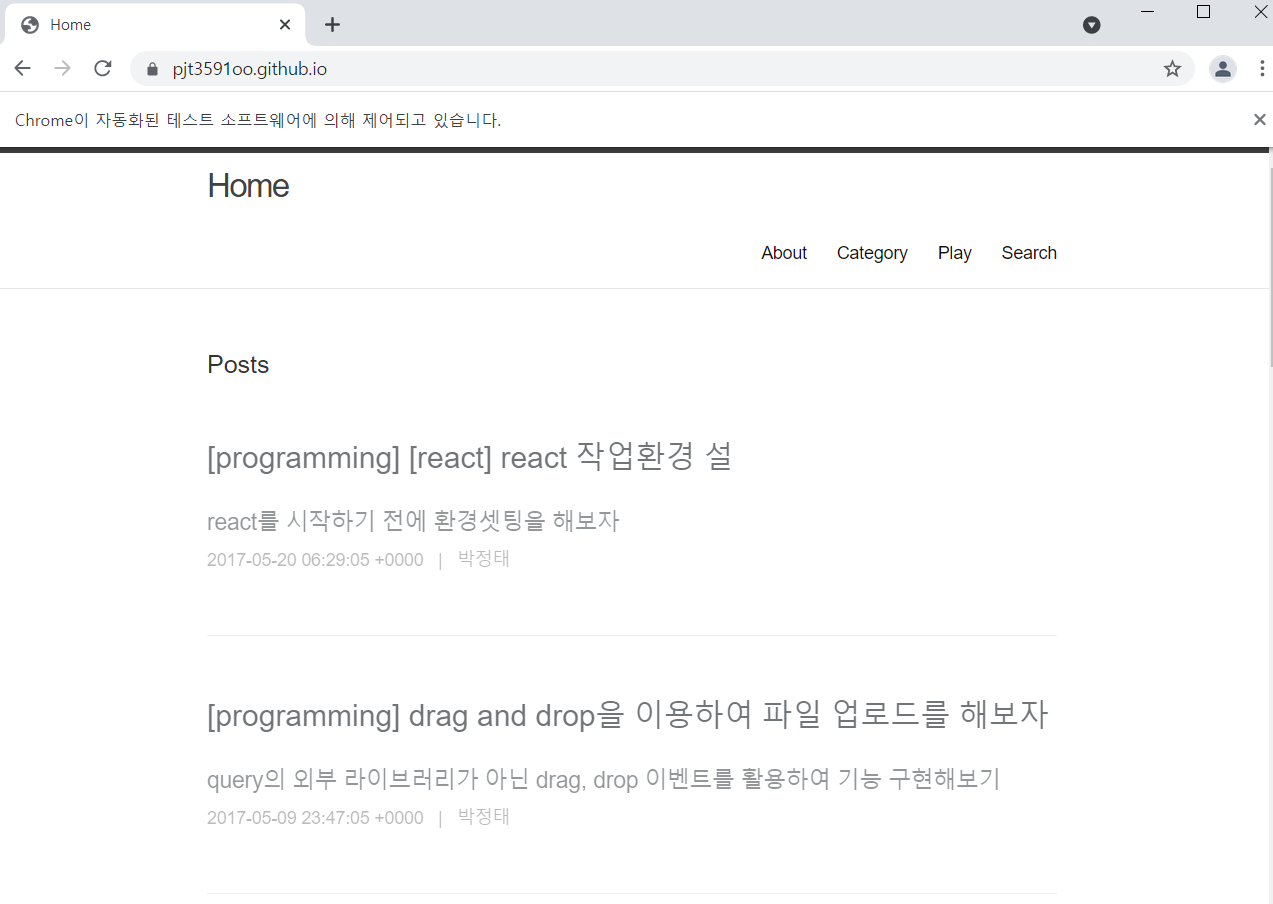
위에 명시한 url로 이동한다.
키보드 제어
driver = webdriver.Chrome('chromedriver')
url = "https://pjt3591oo.github.io/search"
driver.get(url)
selected_tags_a = driver.find_element_by_css_selector('input#search-box')
selected_tags_a.send_keys('test')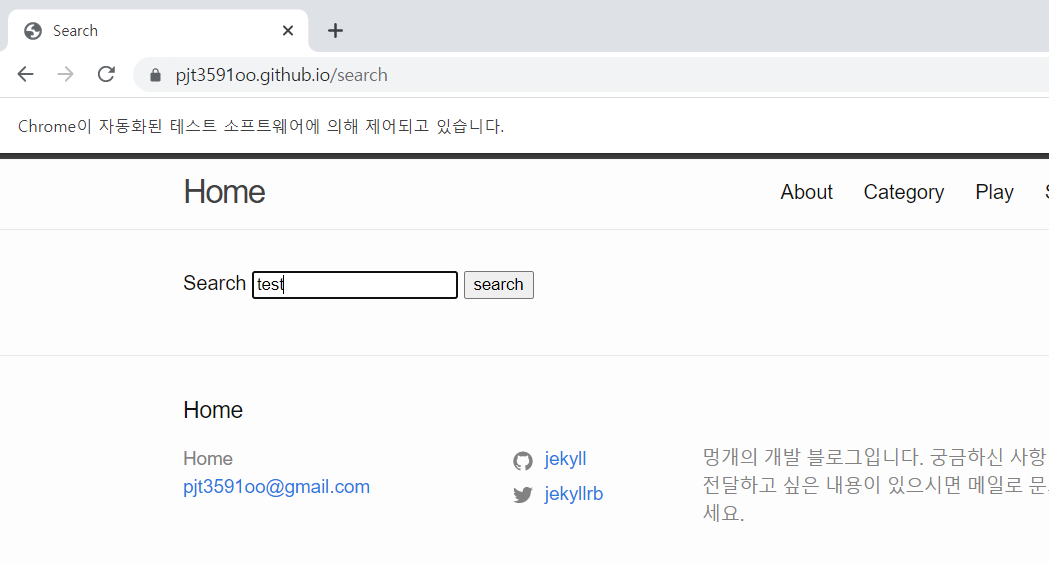
자동으로 test를 입력한 search창이 뜬다.
javascript 실행
driver.get(url)
driver.execute_script('alert("test")')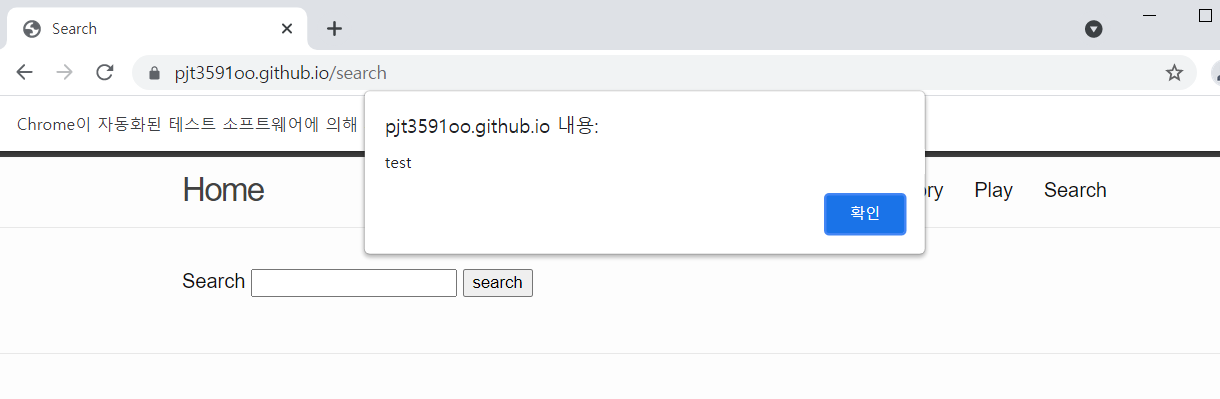
alert 창이 뜬다.
url = "https://pjt3591oo.github.io/search"
search_keyword = 'db'
driver = webdriver.Chrome('chromedriver')
driver.get(url)
selected_tag_a = driver.find_element_by_css_selector('input#search-box')
selected_tag_a.send_keys(search_keyword)
selected_tag_a.send_keys(Keys.ENTER) #\UE007로 해도 엔터가 됨
soup = BeautifulSoup(driver.page_source, 'lxml')
items = soup.select('ul#search-results li')
for item in items:
title = item.find('h3').text
description = item.find('p').text
print(title)
print(description)
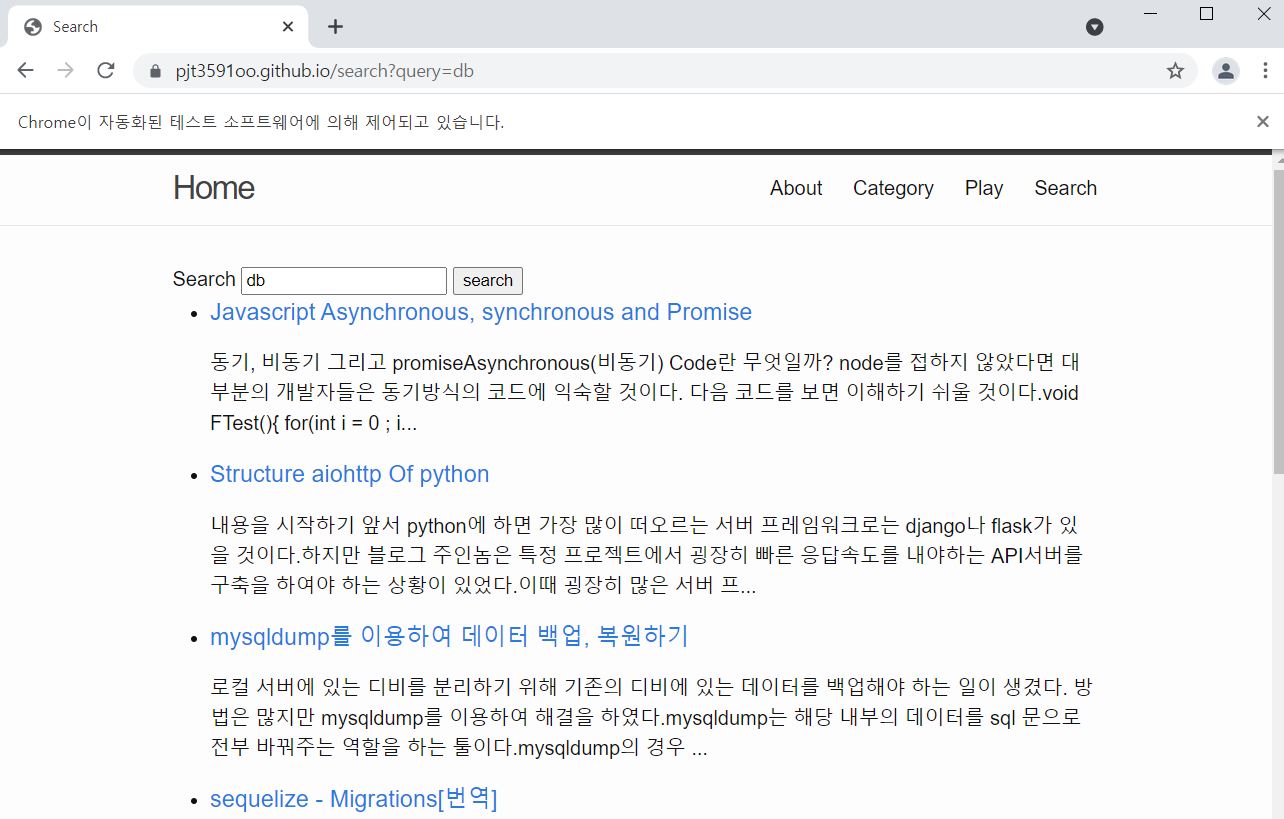
search에 db를 검색한 결과를 띄어준다. 자동으로 브라우저가 열린다.
728x90
반응형
'Data Analysis > web crawling' 카테고리의 다른 글
| [Crawling] Slack Bot 만들기 (0) | 2021.06.09 |
|---|---|
| [Crawling] logging 사용 / 파일에 문서 생성하기 (0) | 2021.06.09 |
| [Crawling] 가상 돔을 활용한 크롤러 / selenium (0) | 2021.06.09 |
| [Crawling] 크롬 드라이버(ChromeDriver) 설치하기 (0) | 2021.06.09 |
| [Crawling] 사이트 분석/ 크롤러 만들기 (0) | 2021.06.08 |