728x90
반응형
* 본 포스팅은 주피터 노트북에서 진행했다.
딕셔너리 객체를 생성한다
person = {'이름':'홍길동','나이':26,'몸무게':87}
person #딕셔너리 객체 만들기
컬럼 값 가져오기
person['이름']person.get('이름')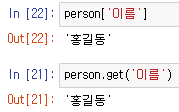
popitem()
person.popitem() #랜덤하게 key와 value를 삭제
clear()
person.clear() #빈객체 만들기
person
딕셔너리 객체가 아래의 사진인 상태에서 for문을 통해 key와 value의 값을 어떻게 불러오는지 확인해 보자
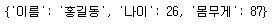
key = person.keys()
value=person.values()
item=person.items() #key와 value를 tuple로 반환for i in value:
print(i)
item은 key와 value 둘다 tuple로 반환한다.
for i in item:
print(i)
key를 이용하여 key와 value를 반환하였다.
for key in person:
print('{} : {}'.format(key, person[key]))
다른 방법도 있다!
for key,value in person.items():
print('{} : {}'.format(key, person[key]))
728x90
반응형
'Language > Python' 카테고리의 다른 글
| [Python/파이썬] 리스트, 튜플, 문자열로부터 집합만들기 / set이용 (0) | 2021.06.02 |
|---|---|
| [Python/파이썬] 튜플(tuple)에 대한 예제 (0) | 2021.06.02 |
| [Python/파이썬] 3차원 리스트를 map을 이용하여 리스트 안의 합을 구하고 1차원 리스트로 변환하기 (0) | 2021.06.02 |
| [Python/파이썬] lambda와 map, filter를 이용한 예제 (0) | 2021.06.01 |
| [Python/파이썬] pop을 이용하여 데이터를 역순으로 하기 /sort, index, insert, pop, remove 이용하기 / list comprehension (0) | 2021.06.01 |