728x90
반응형
* 본 포스팅은 주피터 노트북에서 진행하였다.
requests vs urllib
1. requests와 urllib 요청시 요청 객체를 만드는 방법에 차이가 있다.
2. 데이터를 보낼 때 requests는 딕셔너리 형태로 urllib는 인코딩하여 binary 형태로 전송한다.
3. requests는 요청 메소드(get, post)를 명시하지만 urllib는 데이터의 여부에 따라 get요청, post요청을 구분한다.
4. 없는 페이지 요청시 requests는 에러를 띄우지 않지만 urllib는 에러를 띄운다.
파싱모듈
요청 모듈로 가져온 html 코드를 파이썬이 쓸수있는 코드로 변환해야 함 bs4 모듈을 이용하여 html 코드를 파이썬에서 사용가능한 객체로 바꿔줄 수 있다. bs4는 파이썬 내장 모듈이므로 설치가 필요하지 않다.
파서의 종류
- lxml
- html5lib
- html.parser
크롤러를 만드는데 필요한 선행지식 및 필요한 프로그램 설치 및 문법 습득 requests + bs4 + selenium 이용하여 진행
crawling(긁어온다)
crawler
from bs4 import BeautifulSoup
html = """<p>test</p> """
soup=BeautifulSoup(html,"lxml")
soup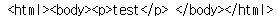
soup=BeautifulSoup(html,"html5lib")
soup
html = """<html> <head><title>test site</title> </head> <body> <p>test</p> </body></html>"""
soup=BeautifulSoup(html,"lxml")
soup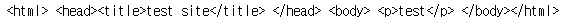
결과를 보기 편하게 하는 방법도 있다. (prettify())
print(soup.prettify())
tag_title=soup.title
print(type(soup),',',type(tag_title))
tag_title.string
tag_title.text
# 같은 결과 나옴
tag_title.name
html = """<html> <head><title class="t" id="ti">test site</title></head> <body> <p>test</p> <p>test1</p> <p>test2</p> </body></html>"""
tag_title = soup.title
print(tag_title.attrs)
print(tag_title['class'])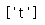
print(tag_title['id'])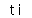
728x90
반응형
'Data Analysis > web crawling' 카테고리의 다른 글
| [Crawling] iterator 만들기 (0) | 2021.06.08 |
|---|---|
| [Crawling] get,[] 차이 / 반복문 이용 (0) | 2021.06.08 |
| [Crawling] 크롤링 get요청, post요청하기 (0) | 2021.06.07 |
| [Crawling] 데이터 보내는 방법 (0) | 2021.06.07 |
| [Crawling] html코드를 가져오기 (0) | 2021.06.07 |

