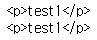with open('4.csv',"a") as f:
column = ','.join(columns) +"\n"
f.write(column)
for i in range(0,len(names)):
row =('%s,%s,%s\n')%(names[i], ages[i], address[i])
f.write(row)
from slackclient import SlackClient
import requests as rq
from bs4 import BeautifulSoup
import time
slack_token = 'xoxb-460297928240-2145122313062-cafL1R4QG7nFNRn4QMIrJeiR' #발급 받은 토큰
sc = SlackClient(slack_token)
#메세지 전달
def notification(message):
sc.api_call(
"chat.postMessage",
channel="#test", #{#채널}의 형태로 채널 지정
text=message
)
selected_id = driver.find_element_by_id('nav-trigger') #id로 요소 선택
print(selected_id)
print(selected_id.tag_name) #태그명
print(selected_id.text) #태그에 속한 문자
selected_p = driver.find_element_by_tag_name('p') #id로 요소 선택
print(selected_p)
print(selected_p.tag_name) #태그명
print(selected_p.text) #태그에 속한 문자
selected_tags_p = driver.find_elements_by_tag_name('p') #id로 요소 선택
print(selected_tags_p)
for post in posts:
title = post.find('h3').text.strip()
descript = post.find('h4').text.strip()
author = post.find('span').text.strip()
print(title,descript,author)
import re
html = """<html> <head><title>test site</title></head> <body> <div><p id="i" class="a">test1</p><p class="d">test2</p></div><p class="d">test3</p></p> a tag <b>b tag</b></body></html>"""
soup = BeautifulSoup(html,'lxml')
print(soup.find_all(class_=re.compile('d'))) # 클래스 값에 d를 포함하는 요소 찾기
print(soup.find_all(id=re.compile('i'))) # id 값에 i를 포함하는 요소 찾기
print(soup.find_all(re.compile('t'))) #태그에 t가 포함되는 요소 찾기
print(soup.find_all(href=re.compile('/'))) #href에 /가 포함된 요소 찾기
정규식은 우리가 문자열을 다룰때 문자열에서 특정 패턴을 검색하거나 바꾸기 위해 사용하는 식이다.
파이썬에서 정규식을 사용하기 위해 re 라는 모듈을 사용한다.
re는 파이썬에 내장되어있으므로 pip를 이용하여 별도의 설치가 불필요하다.
정규식을 사용하기 위한 과정
1. 패턴 만들기, re compile(정규 표현식)을 이용하여 패턴 만들기
2. 만들어진 패턴을 이용하여 match(문자열), search(문자열), findall(문자열), finditer(문자열)을 한다.
3. 위의 과정에서 match(), search()를 통해 나온 결과물을 group(), start(), end(), span()을 이용하여 반환한다.
match와 search는 둘다 함수를 사용하고 일치한 객체가 있으면 반환하고 없으면 null 반환
print('----finditer 결과----')
print(d)
test_a = "a b c d"
예를 보면 알 수 있듯이
match는 문자열의 시작 부분에서만 일치를 확인하는 반면 search는 문자열의 모든 위치에서 일치를 확인한다.
test_str= """I am Park Jeong-tae. I live in Paju.
I lived in Paju for 25 years.
Sample text for testing:
abcdefghijklmnopqrsAvwxyz ABCDEFGHIJKLMNOPQRSTUVWXYZ
0123456789 _+-.,!@#$%^&*();\/|<>"'
12345 -98.7 3.141 .6180 9,000 +42"""
pattern = re.compile('[a-z]')
pattern1 = re.compile('[a-z]+')
c = pattern.findall(test_str) #소문자를 포함하는 것
d = pattern1.findall(test_str) #소문자를 하나라도 포함하는 것
pattern = re.compile('[A-Z]')
pattern1 = re.compile('[A-Z]+')
c = pattern.findall(test_str) #대문자를 포함하는 것
d = pattern1.findall(test_str) #대문자를 하나라도 포함하는 것
pattern=re.compile('[a-zA-Z]')
pattern1 = re.compile('[a-zA-Z]')
c = pattern.findall(test_str) #영문자를 포함하는 것
d = pattern1.findall(test_str) #영문자를 하나라도 포함하는 것
# 전화번호 추출
test_num = "저의 전화번호는 010-6666-7777 입니다"
pattern = re.compile('[0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]') #숫자숫자숫자-숫자숫자숫자숫자-숫자숫자숫자숫자 형태
pattern1 = re.compile('\d\d\d-\d\d\d\d-\d\d\d\d') #숫자숫자숫자-숫자숫자숫자숫자-숫자숫자숫자숫자 형태
pattern2 = re.compile('\d{3}-\d{4}-\d{4}') #숫자숫자숫자-숫자숫자숫자숫자-숫자숫자숫자숫자 형태
c = pattern.findall(test_num)
d = pattern1.findall(test_num)
e = pattern2.findall(test_num)
pattern = re.compile('[a-zA-Z0-9]+') #a부터 z까지, A부터 Z까지, 0부터 9까지 포함된 것
pattern1 = re.compile('\w+') #단어 하나라도 포함된 것
c = pattern.findall(test_str)
d = pattern1.findall(test_str)
pattern = re.compile('t..t') #t문자문자t 패턴
pattern1 = re.compile('t...t') #t문자문자문자t 패턴
c = pattern.findall(test_str)
d = pattern1.findall(test_str)
print(c)
print(d)
test_str = """I am Park Jeong-tae. I live in Paju.
I lived in Paju for 25 years. estadsffjkfad test
Sample text for testing:
abcdefghijklmestnopqrsAvwxyz ABCDEFGHIJKLMNOPQRSTUVWXYZ
0123456789 +-.,!@#$%^&*();\/|<>"'
12345 -98.7 3.141 .6180 9,000 +42"""
pattern = re.compile('t?est\w+') #test나 est로 시작하는 문자열 뒤에 단어(word)가 있어야 함
pattern1 = re.compile('t?est\w*') #test나 est로 시작하는 문자열 뒤에 단어(word)가 없어도 됨
c = pattern.findall(test_str)
d = pattern1.findall(test_str)
print(c)
print(d)