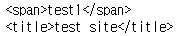* 본 포스팅은 주피터 노트북에서 진행하였다.
from bs4 import BeautifulSoup
html = """<html> <head><title class="t" id="ti">test site</title></head> <body> <p>test</p> <p>test1</p> <p>test2</p> </body></html>"""
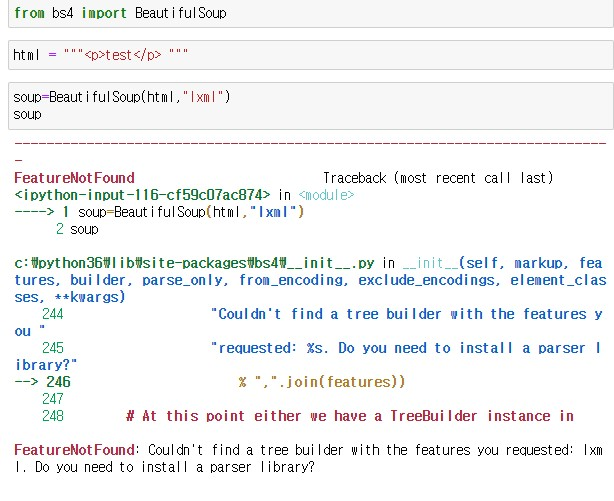
soup = BeautifulSoup(html,'lxml')
tag_title = soup.title
print(tag_title['class'])
tag_title.get('class') #get으로 class의 속성을 가져와라
#둘다 같은 결과
만약 오류가 뜬다면 이대로 입력해주자! 주피터 노트북에서는 코드 앞에 !을 붙이면 된다. cmd로 할 경우 !을 빼면 된다.
!pip install beautifulsoup4
!pip install lxml
tag_title.attrs #attribute

이 둘의 차이는
tag_title.get('class1') #속성이 없는 클래스 호출할 때 get은 오류안뜸
tag_title['class1'] #오류뜸

tag_title.get('class1',default="hi") #값이 없을 때

data_text = tag_title.text
data_text
data_text = tag_title.string
data_text

같은 값을 가져오지만 타입이 다르다
data_text = tag_title.text
data_string = tag_title.sring
print("text : ",data_text, type(data_text))
print('string : ',data_string, type(data_string))

tag_p = soup.p
tag_p

data_text = tag_p.text
data_string = tag_p.string
print('text : ',data_text, type(data_text))
print('string : ',data_string, type(data_string))

html = """<html> <head><title>test site</title></head> <body> <p><span>test1</span><span>test2</span></p> </body></html>"""
soup = BeautifulSoup(html,'lxml')
tag_p = soup.p
tag_p

data_text = tag_p.text
data_string = tag_p.string
print('text : ',data_text, type(data_text))
print('string : ',data_string, type(data_string))

조건문을 활용하여 데이터를 확인할 수 있다. 아래의 코드는 span태그가 있는지의 여부를 묻는다.
if tag_p.span.string !=None:
print('있다')

contents 속성과 children 속성을 이용하여 자식태그를 가져올 수 있다.
contents 속성을 이용하여 list 형태로 자식 태그를 가져온다.
tag_p_children = soup.p.contents
print(tag_p_children)
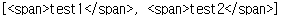
tag_p_children = soup.p.children
tag_p_children #iterate

문제 ) 반복문을 이용하여 둘다 출력하기
예시
a_tuple = (1,2,3)
b_iterator = iter(a_tuple)
print(b_iterator.__next__())
print(b_iterator.__next__())
print(b_iterator.__next__())

이것을 응용하자
tag_p_contents = soup.p.contents
tag_p_contents #[<span>test1</span>, <span>test2</span>]
tag_p_children = soup.p.children
tag_p_children # <list_iterator at 0x243f02ea220>
for i in tag_p_contents:
print(i)

for i in tag_p_children:
print(i)