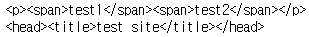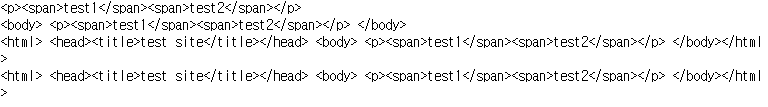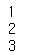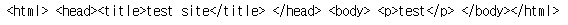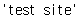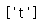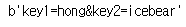728x90
반응형
* 본 포스팅은 주피터 노트북에서 진행하였다.
요소는 태그도 포함하지만 태그로 감싼 문자열로 포함한다.
html = """<html> <head><title>test site</title></head> <body> <p><a>test1</a><b>test2</b><c>test3</c></p> </body></html>"""
soup = BeautifulSoup(html,'lxml')
tag_a=soup.a
tag_a #<a>test1</a>
teg_a_nexts = tag_a.next_siblings
tag_a #<a>test1</a>tag_a = soup.a
tag_a_nexts = tag_a.next_elementsfor i in tag_a_nexts:
print(i)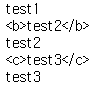
이전 sibling
tag_p_nexts = soup.p.next_elementsprint(soup.prettify())
print('**elements**')
for i in tag_p_nexts:
print(i)
원하는 요소에 정확히 접근하기
find_all을 사용하면된다.
title 태그의 모든것을 가져와라
print(soup.find_all('title'))title 태그의 모든것을 가져와라

print(soup.find_all('p'))p 태그의 모든것을 가져와라

id = 를 이용하여 원하는 id값을 가진 태그를 가져올 수 있고 id값은 해당 페이지에 한번만 사용하므로 하나 또는 빈 리스트 출력된다.
html = """<html> <head><title>test site</title></head> <body> <p>test1</p><p id="d">test2</p><p>test3</p></p> </body></html>"""
soup = BeautifulSoup(html,'lxml')print(soup.find_all(id=True))
print(soup.body.find_all(id=False))
728x90
반응형
'Data Analysis > web crawling' 카테고리의 다른 글
| [Crawling] 정규식을 이용한 bs4 고급 스킬 / 정규식 정리 / match와 search 비교 (0) | 2021.06.08 |
|---|---|
| [Crawling] 클래스 속성을 이용해 태그 가져오기 / find, limit, extract (0) | 2021.06.08 |
| [Crawling] 부모 태그 접근하기 / sibling / generator (0) | 2021.06.08 |
| [Crawling] Generator 만들기 / 자바스크립트 yield와 비교 (0) | 2021.06.08 |
| [Crawling] iterator 만들기 (0) | 2021.06.08 |